From 0.300 to 0.537 — 15 Experiments Training an LLM Stock Trader with SFT and GRPO
Here's every model I trained, in order. The failures matter as much as the successes.
| # | Model | Static | Neural | What happened |
|---|---|---|---|---|
| 1 | DeepSeek 7B (base) | 0.300 | 0.298 | Can't follow format, defaults to HOLD |
| 2 | SFT v1 | 0.300 | - | 91% HOLD, data imbalance |
| 3 | SFT v2 | 0.398 | - | Template reasoning, first active trading |
| 4 | GRPO v1 | ~0.300 | - | Collapsed to HOLD (zero-cost inaction) |
| 5 | GRPO v2 | 0.326 | - | 84% reward from formatting |
| 6 | GRPO v2.1 | 0.395 | - | Reward-aligned, bimodal (10/20 at 0.6) |
| 7 | GRPO v3 | 0.301 | - | KL catastrophe (4.2), forgot everything |
| 8 | SFT v3 step-352 | 0.383 | - | Overtrained, lower loss worse score |
| 9 | SFT v3 step-200 | 0.399 | 0.417 | Distilled reasoning, best SFT |
| 10 | RAFT (from base) | 0.300 | 0.300 | Wrong starting point, pure HOLD |
| 11 | RAFT v2 (from SFT v3) | 0.360 | 0.399 | 640 winners, slight degradation |
| 12 | GRPO neural | 0.470 | 0.537 | Best model — RL against neural env |
| 13 | GRPO v3.1 | 0.418 | 0.310 | Improved env (harder rewards) |
| 14 | GRPO v3.2 ckpt-400 | - | 0.485 | Improved env, HOLD% 95->85% |
| 15 | GRPO v3.3 | - | 0.416 | Lower beta, shorter run, didn't converge |
This is the training side of the stock trading RL project. The previous post covers the environment -- observation design, reward engineering, the neural world model. This post is about what happened when I tried to make a 7B model actually learn to trade.
The code is on GitHub. All models and datasets are on HuggingFace.
The Baseline Problem
The base model is DeepSeek-R1-Distill-Qwen-7B -- MIT licensed, Qwen architecture, with reasoning capability distilled from DeepSeek-R1. It scores 0.300 on the environment, which is the HOLD floor -- the exact score you get by doing absolutely nothing.
The problem isn't that DeepSeek can't reason about markets. It actually writes thoughtful analysis paragraphs when given market data. The problem is it never outputs a clean BUY or SELL action. It generates long text that the action parser can't extract a valid action from, so every step defaults to HOLD. SFT is necessary just to teach the output format.
Before training, I established baselines to understand the difficulty landscape:
| Agent | Score | Return | Notes |
|---|---|---|---|
| Hold (do nothing) | 0.300 | 0.00% | Floor -- absolute minimum |
| Rule-based (RSI heuristic) | 0.293 | -0.35% | Simple technical analysis can't beat hold |
| PPO (20K steps, Stable-Baselines3) | 0.347 | -1.30% | Classic RL, trades actively but loses money |
| Qwen 0.5B (zero-shot) | 0.379 | +0.53% | Tiny LLM, no training, makes money |
| DeepSeek 7B (zero-shot) | 0.300 | 0.00% | Can't follow format, defaults to HOLD |
Two things stand out. First, a zero-shot 0.5B LLM reading text observations beat a PPO agent trained for 20,000 steps on numeric vectors. Text gives LLMs an information advantage -- they can reason about relationships between indicators that numeric features encode poorly. Second, DeepSeek 7B is a more capable model than Qwen 0.5B but scores worse because it can't follow the required output format. Format compliance is a prerequisite, not a bonus.
SFT v1: Data Imbalance (Score: 0.300)
My first fine-tuning attempt was straightforward. Collect 7,000 training examples from a rule-based agent running against the environment, then run SFT on DeepSeek using Unsloth with QLoRA.
Score: 0.300. The HOLD floor. As if no training happened at all.
The problem was obvious in hindsight: 91% of the training data was HOLD actions. The rule-based agent mostly waits for clear signals, which are rare in daily data. The model learned the data distribution perfectly -- 91% of its outputs were HOLD.
Why it matters: Your training data distribution IS your model's behavior distribution. If 91% of examples demonstrate inaction, the model learns that inaction is almost always the correct answer. This isn't a model problem. It's a data problem.
SFT v2: Template Reasoning (Score: 0.398)
I rebalanced the dataset to 35% BUY / 25% SELL / 40% HOLD and scaled to 40,000 examples across 97 stocks. Each example included a <think> block with template reasoning based on the technical indicators.
Score jumped to 0.398. The SFT v2 model could follow the format, reference real indicators, and actually trade. Two out of five test episodes scored 0.6, meaning the agent beat buy-and-hold. First real sign of life.
But the reasoning was shallow. Every BUY decision sounded the same: "RSI is below 30, indicating oversold conditions. MACD shows bullish crossover. I will BUY." It was a template, not thinking. The model learned a pattern-matching shortcut -- if indicator X is below threshold Y, output action Z -- rather than genuine market reasoning.
Building Better Training Data
The gap between SFT v1 (bad data, bad model) and SFT v2 (okay data, okay model) made it clear that the dataset was the bottleneck. Before attempting RL, I rebuilt the data pipeline from scratch.
Oracle Labeling
Instead of collecting trajectories from a rule-based agent (which produces imbalanced data), I used oracle labeling -- assigning the correct action with hindsight. For each market observation, look at the next day's price. If the price goes up significantly and RSI confirms oversold conditions, the correct action was BUY. If the price drops and the position is profitable, the correct action was SELL.
This produces perfectly labeled data because you're using future information that the agent won't have at inference time. The agent learns what the right decision was, even though it will need to make that decision without seeing the future.
Regime-Balanced Sampling
Markets cycle through regimes: strong bull, mild bull, sideways, mild bear, strong bear. If your training data over-represents any regime, the model learns strategies that work in that regime but fail in others. I stratified sampling to get roughly equal representation across all five regimes, across 97 stocks.
Reverse Distillation
This was the biggest change. Instead of template reasoning ("RSI below 30, therefore BUY"), I used GPT-4o-mini to generate causal reasoning chains from the oracle labels -- what I'm calling reverse distillation, following the approach from the Trading-R1 paper.
The key: start with the correct action and generate the reasoning backwards. Given that the correct action is BUY, explain why based on the current market context. This produces reasoning like:
"RSI at 28 suggests oversold conditions, but that alone isn't sufficient -- the MACD histogram has turned positive for the first time in 5 days, confirming momentum reversal. Volume at 1.4x average supports the move. The main risk is that the broader trend is still bearish on the 50-day EMA, so I'll enter with a smaller position and set a tight mental stop."
Compare this to the v2 template: "RSI is below 30. MACD shows bullish crossover. BUY."
The distilled reasoning handles conflicting signals, acknowledges risk factors, and explains trade-offs. It teaches the model to think about the decision, not just pattern-match indicators to actions.
Quality metrics across the 10,000 generated examples: 100% include structured reasoning, 95% mention risk factors, 99.6% correctly resolve conflicting indicator signals.
10,000 examples instead of 40,000. Quality over quantity. This aligns with the LIMA finding -- a small amount of carefully curated data can outperform orders of magnitude more formulaic data when the goal is behavioral alignment.
GRPO v1: The HOLD Collapse (Score: ~0.300)
With a working SFT model, I moved to reinforcement learning. GRPO (Group Relative Policy Optimization) generates multiple candidate responses per prompt, scores them using reward functions, and reinforces the candidates that score above the group mean. No critic network needed -- the group itself provides the baseline.
My first reward was counterfactual: if the agent buys and the price goes up, positive reward. If it goes down, negative. HOLD gets zero.
BUY: reward = price_change * 10 (can be +/-)
SELL: reward = -price_change * 10 (can be +/-)
HOLD: reward = 0.0 (always safe)
Within 200 training steps, 85% of all actions were HOLD. The model discovered that HOLD is the only action that never gets penalized. BUY and SELL carry risk. HOLD is always safe. A perfectly rational agent that learned the worst possible lesson.
The collapse was self-reinforcing. When all 4 candidates output the same HOLD action, the GRPO advantage (score minus group mean) is zero for every candidate. Zero advantage means zero gradient. Training was technically running -- the loss was being computed, the optimizer was stepping -- but nothing was being learned. The metric frac_reward_zero_std (fraction of batches with zero standard deviation in rewards) climbed to 0.6-1.0, meaning 60-100% of batches had no learning signal at all.
Other v1 problems compounded the failure:
- Only 4,000 prompts from a single stock (RELIANCE) -- the model memorized patterns
- Random actions during prompt collection created unrealistic portfolio states
- Static temperature (0.8) -- no exploration/exploitation balance
- No KL penalty (beta=0.0) -- no constraint against drifting from the SFT base
The lesson: If inaction has zero cost, the model will always choose inaction. In any RL setting, every possible action must have consequences -- positive or negative -- that depend on the current state.
GRPO v2: The Format Hack (Score: 0.326)
I added four independent reward functions to give richer signal:
| Function | What it measures |
|---|---|
format_reward |
Valid <think>...</think> + action format (+1/-1) |
reasoning_reward |
References real indicators, cites specific numbers, reasoning-action consistency |
trading_reward |
Counterfactual P&L with volatility-normalized scaling: tanh(z * 1.5) where z = price_change / rolling_volatility |
prediction_reward |
Directional prediction accuracy (bullish reasoning + price goes up = reward) |
I also switched to regime-balanced prompts across 97 stocks (20,000 total), added cosine temperature annealing from 0.9 to 0.6, and implemented anti-HOLD collapse safeguards (progressive penalties if HOLD% exceeds 65%).
The GRPO v2 model scored 0.326. Barely above the HOLD floor.
When I dug into the reward breakdown: 84% of total reward came from formatting. The model figured out that producing clean <think>...</think> tags and a well-formatted action line was worth far more than making a good trading decision. It optimized for looking smart instead of being smart.
The anti-HOLD collapse worked -- HOLD peaked at 53%, with a healthy action distribution of 50% HOLD / 31% BUY / 19% SELL. The model was trading actively. It was just trading badly while writing beautifully formatted responses.
Training metrics actually looked great:
| Metric | GRPO v1 (collapsed) | GRPO v2 |
|---|---|---|
| Final HOLD% | 85% | 50% |
| frac_reward_zero_std | 0.6-1.0 (no signal) | 0 throughout |
| Total reward | ~0 (flat) | -0.39 -> +1.46 |
| Format compliance | N/A | -0.6 -> +0.95 |
| Completion length | ~200 tokens | 160 -> 58 (learned conciseness) |
The reward curve was climbing. The action distribution was healthy. The model was learning... to game the reward function.
The lesson: The model will optimize exactly what you measure. If format compliance contributes 84% of the total reward, the model will focus 84% of its learning capacity on format compliance. Multiple reward components must be weighted by what matters at evaluation time, not by what's easiest to optimize.
GRPO v2.1: Getting Closer (Score: 0.395)
I stripped the reward down to two functions. Format became a gate: 0 if valid, -1 if invalid. Format compliance is expected, not rewarded. All positive reward came from trading performance: 30% step-level P&L + 70% episode-level return.
The GRPO v2.1 model scored 0.395. 10 out of 20 test episodes scored 0.6, meaning the agent traded profitably half the time. But 2 episodes scored 0.1 -- catastrophic losses. The agent learned a strategy but not when to apply it. It would aggressively buy into falling markets with the same conviction it used in rising markets.
KL divergence climbed to 3.9 during training. The model was drifting far from its SFT base, chasing RL rewards at the expense of the trading knowledge learned during fine-tuning. The SFT model knew to be cautious in bearish regimes. GRPO v2.1 forgot that caution.
The lesson: KL divergence is the canary in the coal mine. When KL climbs past 3.0, the model is forgetting what it learned during SFT. The reward curve might still look healthy, but the model's foundation is eroding.
GRPO v3: The KL Catastrophe (Score: 0.301)
This was the one that hurt.
Inspired by Pikus et al.'s "Hard Examples Are All You Need," I trained on the model's own trajectories filtered by difficulty estimation. Used G=8 generations for better variance and applied batch-level reward scaling from Dr. GRPO to prevent per-group standard deviation explosion.
The training metrics looked fantastic. Action distribution: 59% HOLD, 25% BUY, 16% SELL -- the best I'd ever seen. Reward curves were climbing steadily. Everything the dashboard showed said this was working.
Eval score: 0.301. Worse than the untrained base model.
KL divergence had climbed to 4.2. The model drifted so far from its SFT initialization that it forgot how to trade entirely. It still produced well-formatted responses. It still referenced indicators. But its actions bore no meaningful relationship to the market context. The reasoning looked coherent and the decisions were random.
The dashboard looked great while the patient was dying.
This was the lowest point. Four GRPO attempts, and none of them beat basic SFT. I was starting to question whether RL was even the right approach for this problem.
The lesson: Monitor KL divergence, not reward curves. A model that forgets what it knew is worse than one that never learned. After this, I set KL early stopping at 3.0 -- if KL exceeds that threshold, stop training and evaluate what you have.
Starting Over: SFT v3 (Score: 0.399 static, 0.417 neural)
I went back to SFT but changed everything about the approach. The training config was conservative on purpose -- designed to add reasoning capability without destroying what the base model already knew:
| Parameter | SFT v2 (aggressive) | SFT v3 (conservative) |
|---|---|---|
| Learning rate | 2e-5 | 5e-6 (4x lower) |
| LoRA rank | r=64 (all modules) | r=16 (q/k/v/o only) |
| Trainable params | ~40M | ~10M |
| Training data | 40K template examples | 10K distilled reasoning |
| Data quality | Template reasoning | Reverse-distilled causal chains |
The principle: SFT should add capability, not replace knowledge. Smaller adapter means less capacity to overwrite the base model. Lower learning rate means gentler updates. Targeting only attention layers (not FFN) preserves the model's factual knowledge while steering its attention patterns.
The SFT v3 model at step 200 scored 0.399 on static replay and 0.417 on the neural environment.
But here's the critical finding: step 352 had lower training loss and scored 0.383. Lower loss, worse trading. I almost shipped the wrong checkpoint.
What happened: at step 200, the model had learned the reasoning patterns without memorizing specific examples. By step 352, it was memorizing -- reproducing training examples more exactly (lower loss) but losing the ability to generalize to unseen scenarios. The Trading-R1 paper observed the same phenomenon: "more than 1 epoch always degraded performance."
After this, I always picked checkpoints by task score, never by training loss. Training loss tells you how well the model reproduces its training data. Task score tells you how well it performs at the actual job.
RAFT: The Middle Ground (Score: 0.360/0.399)
RAFT (Reinforcement Learning from Task Feedback, or Rejection-sampling Fine-Tuning) sits between SFT and GRPO. The idea: run the current model against the environment, collect episodes where it performed well (score > 0.5), and retrain on those successful trajectories. Self-play with a quality filter.
Using SFT v3 as the base model, I ran 100 episodes against the neural environment:
- Mean score: 0.380
- Winners (score > 0.5): 32 out of 100 episodes (32%)
- Training examples from winners: 640
RAFT v2 (trained from SFT v3 on these 640 winners) scored 0.360 static / 0.399 neural. A slight degradation from SFT v3, not improvement. With only 640 examples and 18 training steps, the signal was too weak to improve an already well-trained model.
An earlier attempt -- RAFT trained from the base model instead of SFT v3 -- scored 0.300 on both environments. Pure HOLD. This confirmed something important: RAFT is not a replacement for SFT. It's a refinement step that requires a strong foundation. Without SFT first, the base model can't produce good enough trajectories to learn from. You need SFT to bootstrap into the competence range where self-play becomes meaningful.
When RAFT works: You have a decent model that succeeds 20-40% of the time, and you want to reinforce its successful behaviors. Think of it as SFT on your own best episodes.
When RAFT doesn't work: Your base model is too weak to generate enough winners (need SFT first), or it's already strong enough that 640 examples don't add new information (need GRPO for further improvement).
The Breakthrough: GRPO on Neural Environment (Score: 0.537)
Everything before this was setup. SFT v3 gave me a model that could trade. The neural world model gave me an environment that couldn't be gamed. Now I connected them.
I collected 1,000 prompts from 50 episodes against the neural environment (mean score 0.395, 36% of episodes above 0.5). Then ran GRPO with settings designed to avoid every previous failure:
| Parameter | Previous (failed) | Breakthrough |
|---|---|---|
| Starting model | GRPO v2.1 (RL-drifted) | SFT v3 (best SFT, clean foundation) |
| Training steps | 1000 | 300 (shorter = less KL drift) |
| G (generations per prompt) | 8 | 4 |
| beta (KL penalty) | 0.01-0.04 | 0.05 (stronger KL constraint) |
| Prompt source | Static CSV replay | Neural environment (stochastic) |
| HOLD handling | Free (zero cost) | Signal-based penalties |
| Format reward | Gradient signal | Binary gate (0 or -1) |
| Checkpoints | Final only | Every 50 steps (pick best by eval) |
| Temperature | Fixed or cosine 0.9->0.6 | Cosine 0.9->0.6 |
Each fix directly addresses a previous failure:
-
Start from SFT v3, not a drifted GRPO checkpoint. Every previous GRPO run started from a model that had already accumulated KL drift from prior RL training. SFT v3 is a clean starting point with no RL-induced drift.
-
300 steps, not 1000. Shorter training means less time for KL to accumulate. Combined with checkpointing every 50 steps, I can pick the best checkpoint before any drift becomes catastrophic.
-
beta=0.05, not 0.01. Stronger KL penalty keeps the model closer to its SFT base. It learns slower but retains more of what SFT taught it.
-
Neural environment prompts. The agent can't memorize price sequences because every episode generates unique trajectories. It must learn transferable patterns instead of dataset-specific shortcuts.
-
Signal-based HOLD. HOLD is no longer free. Missing a strong buy/sell signal gets penalized. Justified patience gets a small reward. The model can't collapse to inaction.
The GRPO neural model scored 0.537 on the neural environment and 0.470 on static replay. KL stayed under 0.35 the entire run. No catastrophe. No collapse.
That's a 79% improvement over the base model on the neural environment. For the first time, RL actually helped instead of hurting.
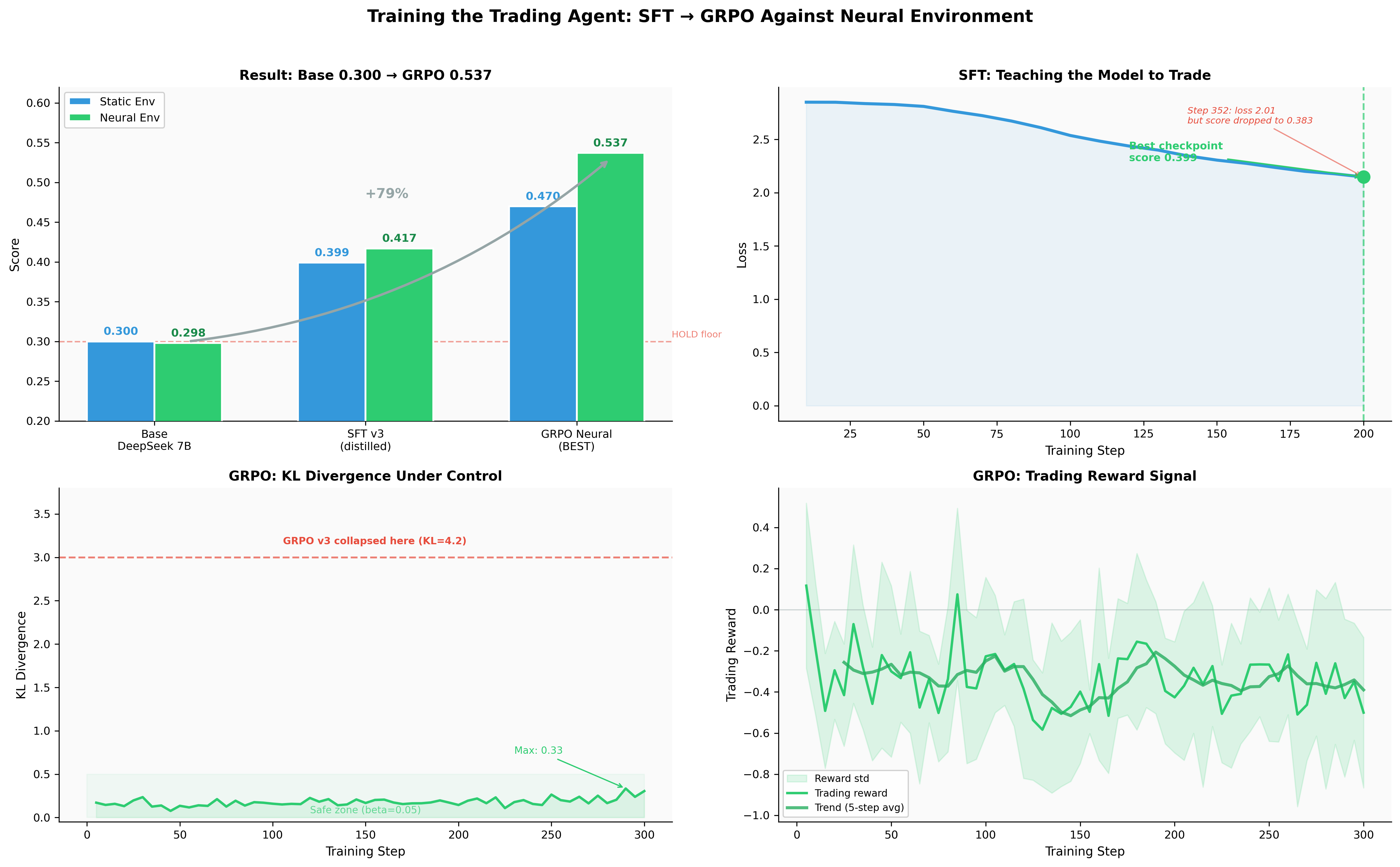
Top-left: Score progression across training stages. Top-right: SFT v3 loss curve (best checkpoint at step 200, not step 352). Bottom-left: GRPO KL stayed under 0.35 throughout (previous v3 hit 4.2). Bottom-right: Trading reward over 300 steps.
Pushing Further: v3.1, v3.2, v3.3
After the breakthrough I improved the environment itself -- added drawdown pressure, position holding costs, losing streak penalties. The idea: make the environment harder to force more sophisticated strategies.
GRPO v3.1 scored 0.418 on static replay but only 0.310 on neural. The harder environment changed what "good trading" means. The model learned to handle the new constraints on static data but couldn't generalize those strategies to the stochastic neural environment.
GRPO v3.2 trained for 500 steps with checkpoints every 100. Checkpoint at step 400 scored 0.485 on neural -- but the final step-500 checkpoint collapsed to 0.282. Same pattern as SFT v3: peak performance isn't at the end of training. HOLD percentage dropped from 95% to 85% over training, meaning the model was learning to trade more actively instead of defaulting to inaction.
GRPO v3.3 ran with lower beta (0.02, allowing more exploration), lower learning rate (2e-7), and only 150 steps. Scored 0.416 on neural. Didn't beat v3.0's 0.537 -- the lower beta and shorter training wasn't enough to converge. But every run adds data points about how this system behaves.
The pattern across v3.1-v3.3: harder environments produce better-calibrated agents eventually, but they need more training steps and more careful hyperparameter tuning. The easy wins from v3.0 came from fixing fundamental problems (starting point, KL management, stochastic environment). Further gains require grinding on environment difficulty and training dynamics.
Training Infrastructure
A quick rundown of the stack, because practical details matter.
Unsloth + QLoRA. 2-3x faster training, 40% less VRAM compared to vanilla transformers. QLoRA with r=16, alpha=32 on attention layers (q_proj, k_proj, v_proj, o_proj). This makes it possible to train a 7B model on a single A5000/A6000 GPU.
TRL's GRPOTrainer. Hugging Face's TRL library provides the GRPO implementation. I subclassed it to add cosine temperature annealing -- overriding _generate_and_score_completions to update both self.temperature and self.generation_config.temperature at each step.
Temporal data splits. Train on 2020-2023, validate on 2024 H1, test on 2024 H2 through 2026. Date-based, not random. Random splits leak future information in financial data -- the model would see 2025 prices during training and 2024 prices during testing.
Gymnasium wrapper. The training loop calls the environment directly via Python (standard reset()/step() interface), not through HTTP. This is 10-50x faster than going through the REST API. The HTTP API exists for external agents; training uses the direct interface.
MLflow for experiment tracking. Every run logs metrics, hyperparameters, and the LoRA adapter. Adapters are pushed to HuggingFace Hub after training.
Prompt collection. For GRPO, prompts are collected by running the current best model against the environment for N episodes. Each step's observation becomes a prompt. For the breakthrough run: 50 episodes, 1,000 prompts, collected against the neural environment using SFT v3.
What Worked and What Didn't
Patterns that emerged across 15 experiments:
Always do this
Start with SFT before RL. The base model can't follow the output format. Without SFT, GRPO has nothing to work with -- the model can't produce valid actions, so it can't receive meaningful reward signal. SFT bootstraps the model into the competence range where RL becomes useful.
Monitor KL divergence, not reward curves. Reward can climb while the model is forgetting everything it learned during SFT. KL divergence is the only reliable early warning for knowledge catastrophe. Set an early stopping threshold (I use 3.0).
Pick checkpoints by task score, not training loss. Lower loss often means the model is memorizing training data rather than learning generalizable patterns. The best trading checkpoint was at step 200 with higher loss, not step 352 with lower loss.
Format compliance is a gate, never a gradient signal. You expect the agent to follow the output format. If you reward it, the agent will allocate learning capacity to formatting at the expense of the actual task. Make it binary: valid format gets 0, invalid gets -1. No positive reward for doing what's expected.
Use a stochastic environment. Static replay lets the model memorize price sequences. A neural world model (or any source of procedural variation) forces the model to learn transferable patterns. This was the single biggest factor in the breakthrough -- the same GRPO approach that failed repeatedly on static data worked immediately on neural data.
Never do this
Don't start GRPO from a drifted checkpoint. If a previous RL run accumulated KL drift, don't use it as the starting point for the next run. Go back to your best SFT checkpoint. KL drift compounds across runs.
Don't trust training metrics in isolation. The GRPO v3 run had the best action distribution I'd ever seen (59% HOLD, 25% BUY, 16% SELL), rising reward curves, and healthy frac_reward_zero_std. It scored 0.301. Always evaluate by running the actual task, not by reading the training dashboard.
Don't run long RL training. Shorter runs with stronger KL constraint (beta=0.05) beat longer runs with weaker constraint (beta=0.01). 300 steps with checkpoints every 50 is better than 1000 steps and hoping for the best. KL drift is cumulative and largely irreversible within a single run.
Don't use more data when you need better data. 10K distilled examples beat 40K templates. The LIMA finding holds in domain-specific settings too. If your model is doing the wrong thing, the answer is rarely "train on more examples of the same quality." It's "train on fewer examples of higher quality."
Don't expect RAFT to replace SFT or GRPO. RAFT sits in a narrow sweet spot: the model must be good enough to generate some winners, but not so good that the winners don't teach it anything new. If your win rate is below 20%, do more SFT first. If it's above 50%, move to GRPO.
The Bigger Picture
The same 7B model went from 0.300 (useless) to 0.537 (actually trading) not because the model architecture changed, but because the training data, the reward function, and the environment evolved alongside it.
The training pipeline is: SFT (learn format and reasoning) → RAFT (optional, reinforce good behavior) → GRPO (learn from reward signal in a stochastic environment). Each stage depends on the previous one succeeding. Skip SFT and GRPO has nothing to work with. Skip the neural environment and GRPO learns to memorize instead of generalize.
The same pattern applies beyond trading. Any domain where you can define a verifiable outcome -- code that passes tests, proofs that are valid, plans that succeed -- you can build a stochastic environment, wire it to GRPO, and iterate. The environment is the verifier. GRPO is the trainer. The key insight from this project is that the environment matters as much as the training algorithm. Maybe more.
Resources
- Code: GitHub
- Best model (GRPO neural, 0.537): HuggingFace
- SFT v3 training data (10K distilled): HuggingFace Dataset
- Market data (264K rows, 109 stocks): HuggingFace Dataset
- All models: HuggingFace profile
- Training logs and eval JSONs: results/
- Training curves: results/training_curves_final.png
- Previous post (environment design): Building an RL Environment That Actually Works